getwd()R Projects & Importing Data
0.1 Learning Objectives
- Describe what an R Project is
- Outline how an R Project affects the file paths used to read in data
- Read in data from common formats into R
- Identify missing data and type of missingness
📖 Readings: 15-20 minutes
💻 Activities: 30 minutes
✅ Check-ins: 1
1 Directories, Paths, and Projects
We have learned how to organize our personal files and locate them using absolute and relative file paths. The idea of a “base folder” or starting place was introduced as a working directory. In R, there are two ways to set up your file path and file system organization:
- Set your working directory in
R(do not recommend) - Use R Projects (preferred!)
1.1 Working Directories in R
To find where your working directory is in R, you can either look at the top of your console or type getwd() into your console.
Although it is not recommended, you can set your working directory in R with setwd():
setwd("/path/to/my/assignment/folder")
File Paths in
R
A quick warning on file paths is that Mac / Linux and Windows differ in the direction of their backslash to separate folder locations. Mac/Linux use / (e.g. STAT210/Week1) while Window’s uses \ (e.g. STAT210\Week1).
1.2 R Projects
📖 Review Reading: Workflow (R Projects)
Only read Section 6.2!
Create an R Project from an Existing Folder
So far, each time we have worked in R we have created an R Project. The R Project lives in the created folder for two reasons, (1) when you copy a GitHub repository you told RStudio you wanted to make a new R Project, and (2) in order for RStudio to talk with GitHub you need to use an R Project.
However, if you look in any other folder on your computer, you should not see a blue cube since you never created an R Project in those folders. Suppose we have a project we’ve been work on and we never created an official R Project for it (perhaps it is a folder filled with data sets or someone sent a zipped filed that didn’t contain an R Project file (.RProj).
To add a R Project to an existing folder on your computer (e.g., you already created a folder for the project), first open RStudio on your computer and click File > New Project, then select Existing Directory:
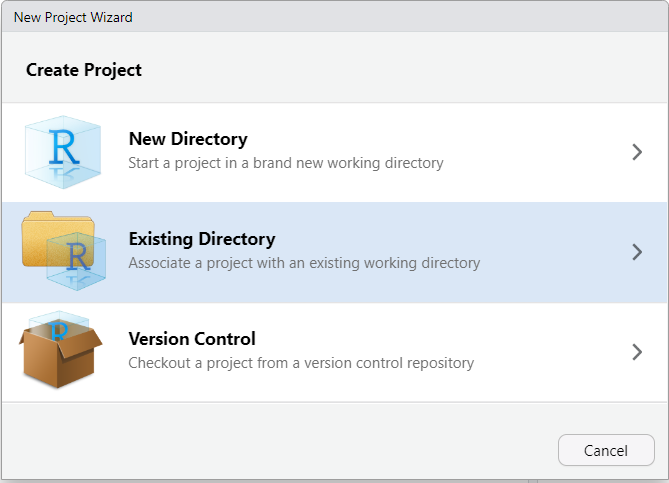
Then, browse on your computer to where you saved your project folder (it should be on your hard drive and not on iCloud, Google Drive, or One Drive). For example, let’s say you ahd a folder called STAT331 that you wanted to turn into a R Project. Select that folder.
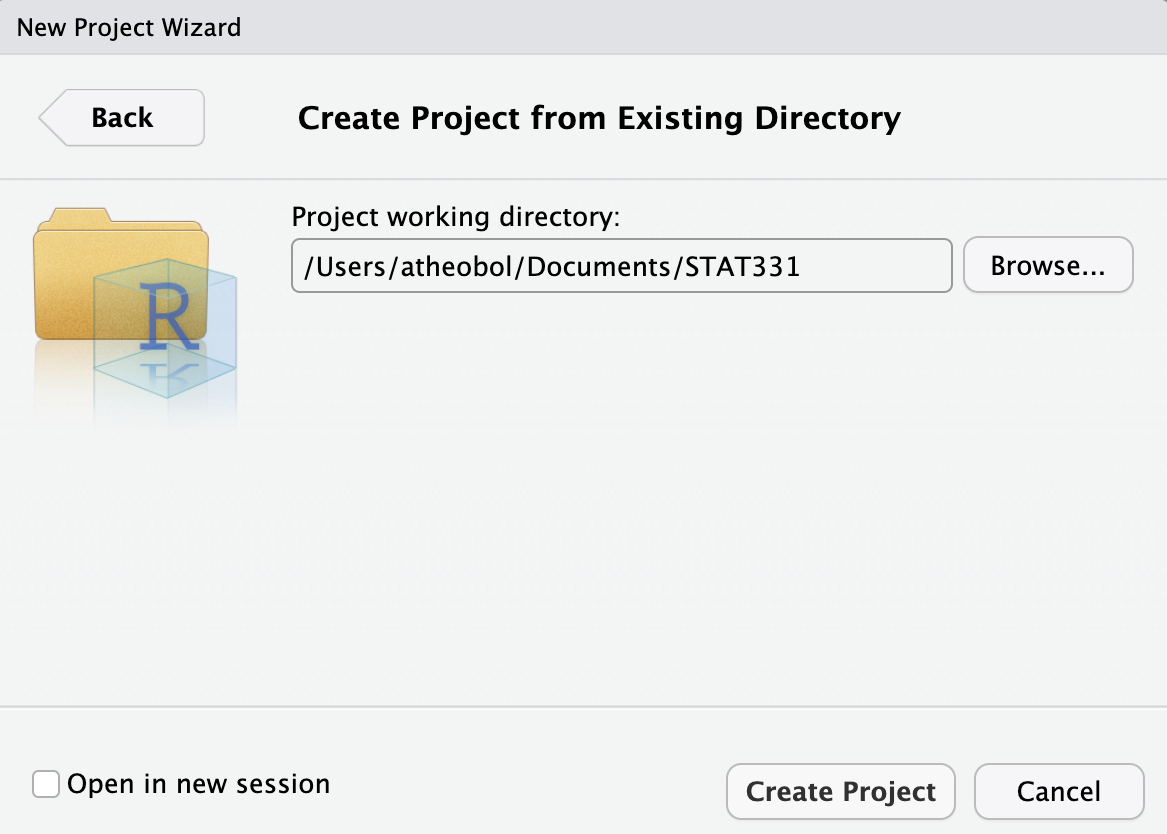
Once you click “Create Project”, your existing folder, STAT331 should now contain a STAT331.Rproj file. This is your new “home” base for this class - whenever you refer to a file with a relative path it will begin to look for it here.
If you would like a list of step-by-step instructions for this process, feel free to look at this file: Creating a Project in an Existing Directory
2 Loading Data Into R
2.1 How do I load my data?
2.2 Where does my data live?
✅ Check-in: Loading Data
For this check-in you are asked to work through reading in different data sets. You are expected to create your own Quarto document to complete this activity.
The folder Age_Data contains several data sets with the names and ages of five individuals. The data sets are stored as different file types. Download Ages_Data.zip here, make sure to unzip the folder, save these in a reasonable place (e.g., STAT210 > Week 5 > Checkins or STAT210 > Checkins > Week 5).
Extracting zip folders
You will need to extract the contents of the ages.zip file, that means you will need to uncompress the files from the folder for RStudio to know where to get the data from.
3 Tidy Data
3.1 Tidy Data

3.2 Same Data, Different Formats
Different formats of the data are tidy in different ways.
| Team | Points | Assists | Rebounds |
|---|---|---|---|
| A | 88 | 12 | 22 |
| B | 91 | 17 | 28 |
| C | 99 | 24 | 30 |
| D | 94 | 28 | 31 |
| Team | Statistic | Value |
|---|---|---|
| A | Points | 88 |
| A | Assists | 12 |
| A | Rebounds | 22 |
| B | Points | 91 |
| B | Assists | 17 |
| B | Rebounds | 28 |
| C | Points | 99 |
| C | Assists | 24 |
| C | Rebounds | 30 |
| D | Points | 94 |
| D | Assists | 28 |
| D | Rebounds | 31 |
3.3 Connection to ggplot
Let’s make a plot of each team’s statistics!
Code
ggplot(data = bb_wide,
mapping = aes(x = Team)) +
geom_point(mapping = aes(y = Points,
color = "Points"),
size = 4) +
geom_point(mapping = aes(y = Assists,
color = "Assists"),
size = 4) +
geom_point(mapping = aes(y = Rebounds,
color = "Rebounds"),
size = 4) +
scale_colour_manual(
values = c("darkred",
"steelblue",
"forestgreen")) +
labs(color = "Statistic")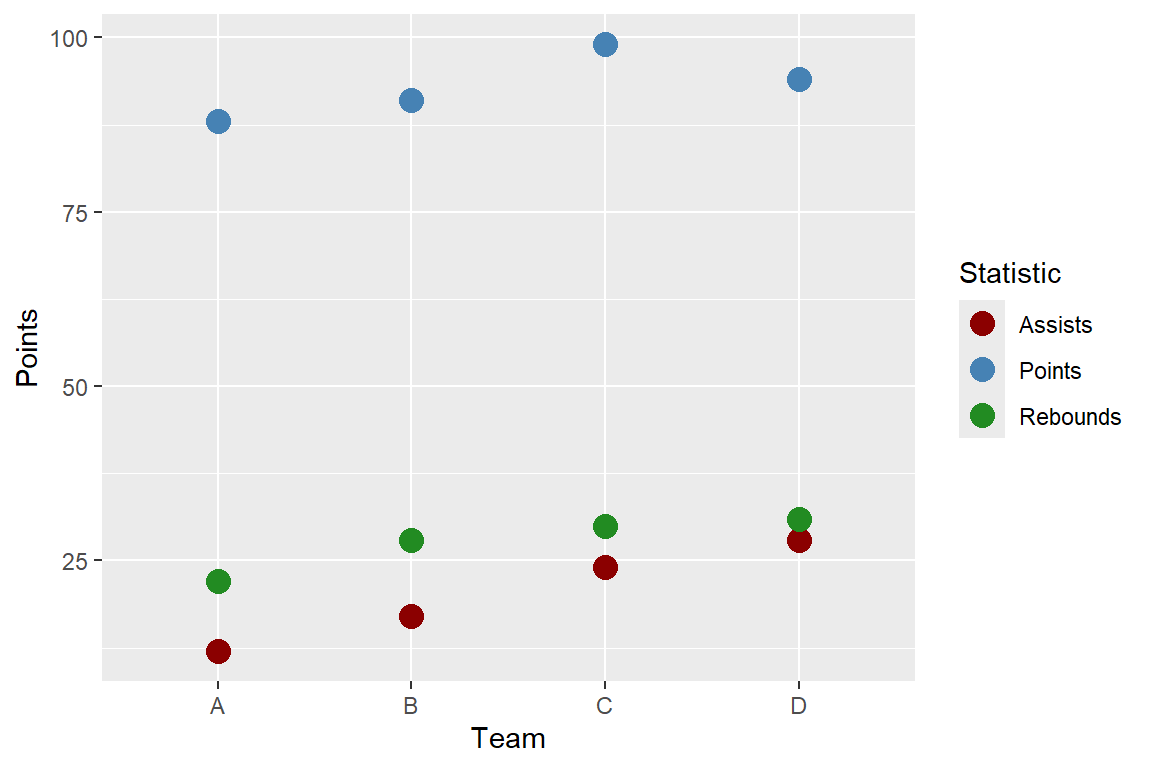
Code
ggplot(data = bb_long,
mapping = aes(x = Team,
y = Value,
color = Statistic)) +
geom_point(size = 4) +
scale_colour_manual(
values = c("darkred",
"steelblue",
"forestgreen")) +
labs(color = "Statistic")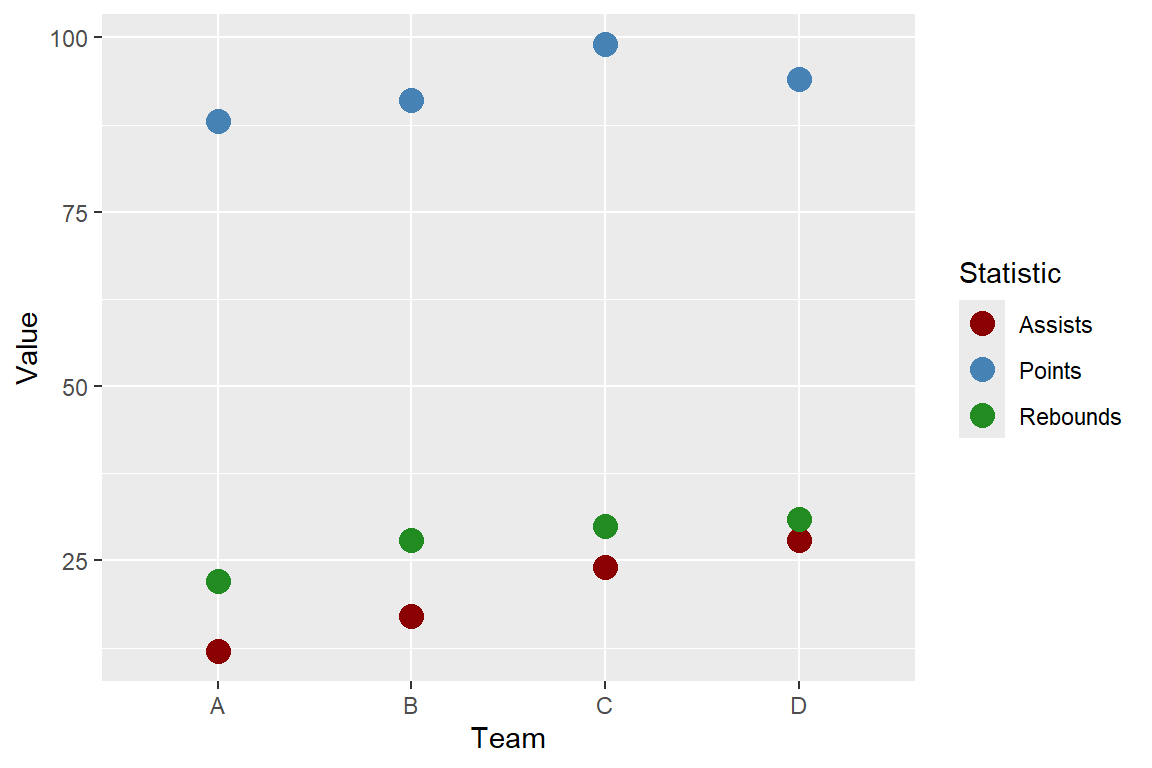
3.4 Tidy Data

4 Working with External Data
4.1 Common Types of Data Files
Look at the file extension for the type of data file.
. . .
.csv : “comma-separated values”
Name, Age
Bob, 49
Joe, 40. . .
.xls, .xlsx: Microsoft Excel spreadsheet
- Common approach: save as
.csv - Nicer approach: use the
readxlpackage
. . .
.txt: plain text
- Could have any sort of delimiter…
- Need to let R know what to look for!
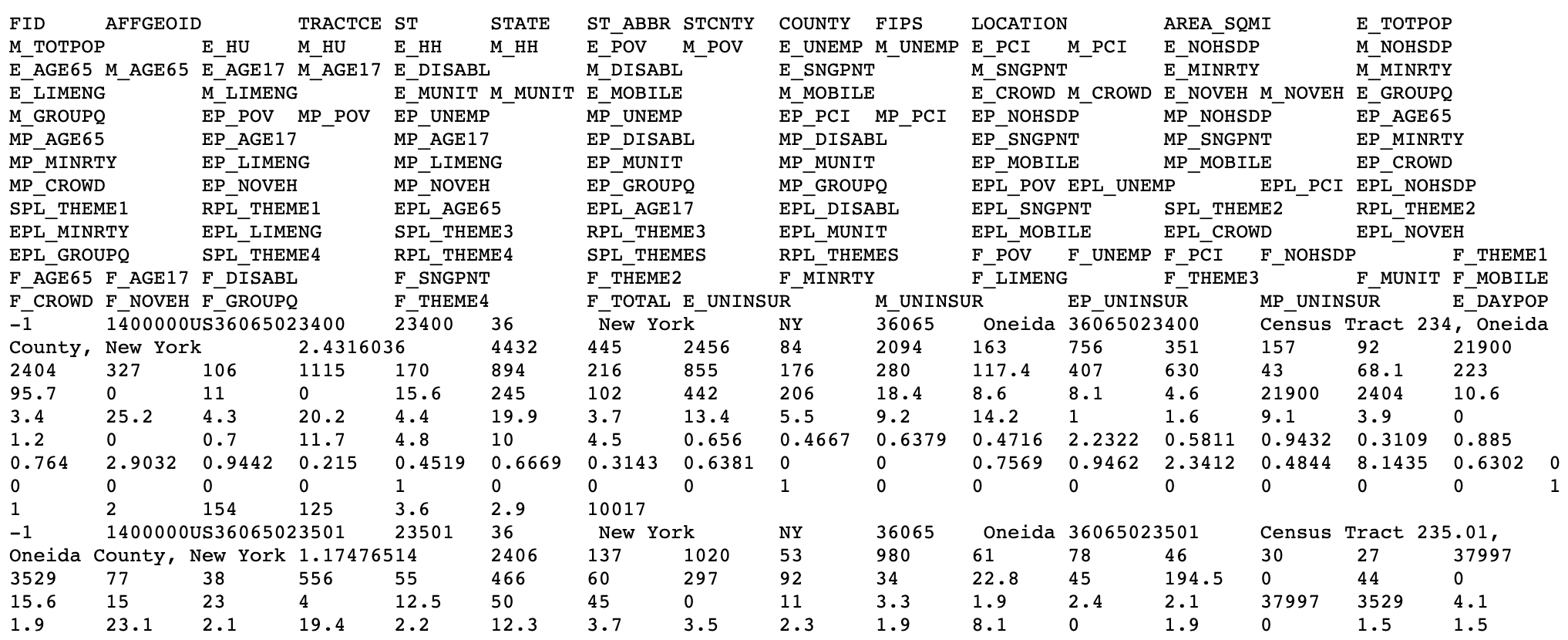
4.2 Common Types of Data Files
What is the delimiter (e.g. comma, tab, space, etc.) for each data file?


4.3 Loading External Data
Using base R functions:
read.csv()is for reading in.csvfiles.read.table()andread.delim()are for any data with “columns” (you specify the separator).
4.4 Loading External Data
The tidyverse has some cleaned-up versions in the readr and readxl packages:
readrpackage is loaded withlibrary(tidyverse)read_csv()is for comma-separated data.read_tsv()is for tab-separated data.read_table()is for white-space-separated data.read_delim()is any data with “columns” (you specify the separator). The above are special cases.
readxlwill need need to be loaded separately withlibrary(readxl)read_xls()andread_xlsx()are specifically for dealing with Excel files.
Remember to load the readr and readxl packages first!
4.5 What’s the difference?
Compare the two functions read.csv() and read_csv() - what do you notice about the possible arguments you can use in each? Why is read_csv() the better option?

4.6 Practice with Importing Data
Once you have the data saved (and extracted) in your STAT 210 folder, preferably in the Week 5 subfolder, use the readr and readxl packages to complete the following exercises.
- Load the appropriate packages for reading in data.
- Read in the data set ages.csv
- Read in the data set ages_tab.txt
- Read in the data set ages_mystery.txt
- Read in the data set ages.xlsx
- Find a way to use
read_csv()to read ages.csv with the variable “Name” as a factor data type and “Age” as a character data type.
4.7 Import Multiple Files at Once
If you have multiple files that are organized the same way (same variables names/columns), you can actually import them all at once and combine into one file. Check out the following tutorial: